Build LL(1) Parse Table
How to Build LL(1) Parse Table
The type of LL parsing in JFLAP is LL(1) Parsing.
The first L means the input string is
processed from left to right.
The second L means the derivation
will be a leftmost derivation (the leftmost variable is replaced at
each step).
1 means that one symbol in the input string is used
to help guide the parse.
We will begin by loading the grammar. You can either enter the grammar (shown below) or load the file grammarToLL.jff.
Now click on Input and then Build LL(1) Parse Table. Your window should look like this after entering LL(1) Parse Table mode.
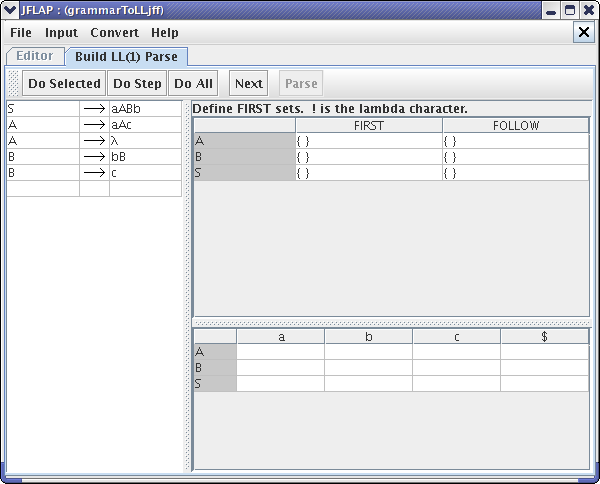
Now, the first step is to enter in FIRST sets. A FIRST set of a string of variables and terminals is the set of terminals that can first appear in the derived string. For instance, variable “A” can derive either lambda or some string that starts with “a”. Thus, we should put “a” and lambda in the FIRST set for variable “A”. You can enter lambda by writing “!”. We can fill in the FIRST set of start variable “S” by putting terminal “a” in the set, since the “S” production begins with terminal “a”.
*NOTE : When you want to enter two terminals into a set, just write them without any spaces. For example in order to put lambda and terminal “a” into the FIRST set of “A”, you would simply type “!a” in the appropriate column.
After entering FIRST sets for variables “S” and “A”, your LL(1) Parse window should look like this :
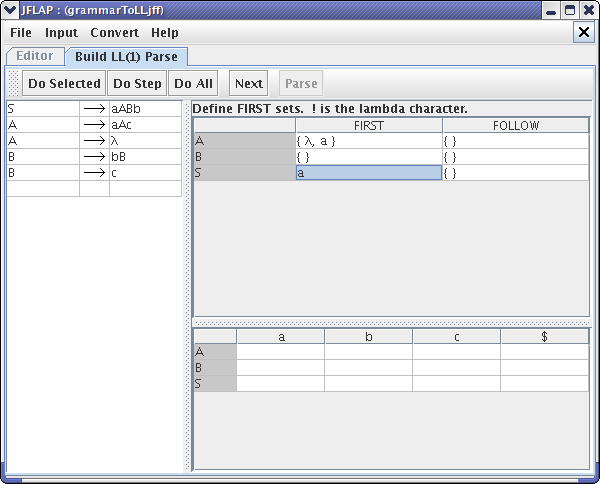
Now we have to enter the FIRST set for variable “B”. Suppose we enter “d” as the FIRST set of variable “B”. Clearly, the variable “B” does not produce any string that would begin with “d”. JFLAP detects this error when you press NEXT button.
You would receive an error message like this one :
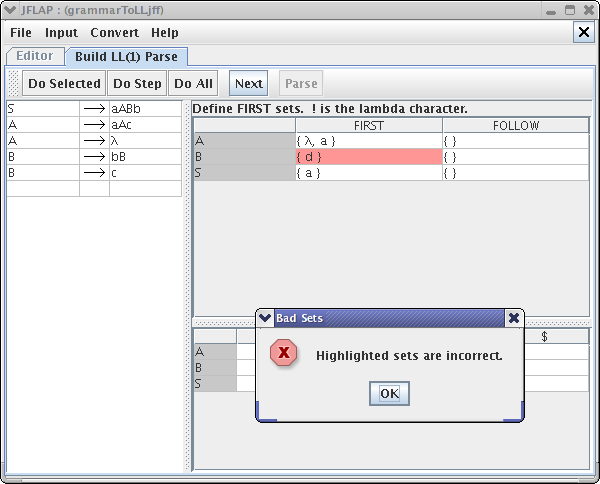
After correcting the error by entering “b” and “c” as the FIRST set of variable “B”, we can click Next. If our FIRST sets are all correct then a message tells us to define FOLLOW sets.
Now, we need to enter the proper FOLLOW sets for each variable as we did for the FIRST sets. The FOLLOW set of variable “X” is a set of terminals that can immediately follow “X” in some derivation.
The FOLLOW set for variable “A” contains terminal “c” and “b”. It is quite obvious to notice that terminal “c” follows variable “A” in production “A->aAc”. However, it is not quite obvious to see where the terminal “b” follows variable “A”. In the first production, variable “B” follows variable “A”. Since variable “B” starts with terminal “b” or “c”, we can conclude that these terminals will follow variable “A” as well.
*NOTE : $ is a special marker that is always in the FOLLOW set of the start variable. This marker is placed at the end of a string to indicate the end of the string in parsing. The FOLLOW set for start variable “S” is only $, since there are no variables or terminals that follow start variable “S”.
After entering all the FOLLOW sets, click Next. If your FOLLOW sets are all correct, your LL(1) Parse Table should look like this :
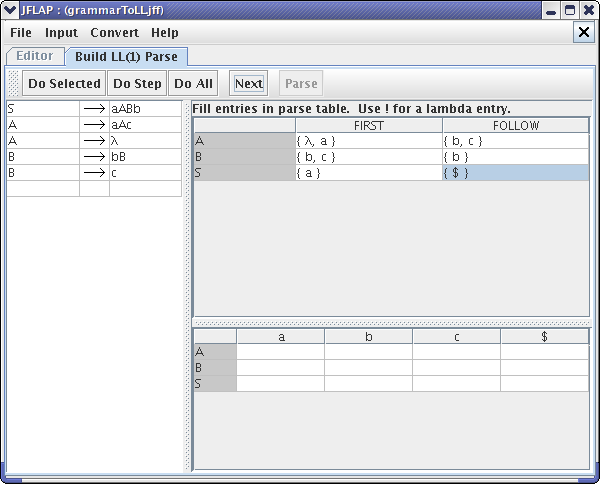
There are two main rules for filling in the table. 1) For production “A->w”, for each terminal in FIRST(w), put w as an entry in the A row under the column for that terminal. 2) For production “A->w”, if lambda is in FIRST(w), put w as an entry in the A row under the columns for all symbols in the FOLLOW(A).
Now, it's time to fill entries in the parse table. For production “A->aAc”, we put “aAc” in column “a” in row “A”. For production “A->lambda”, we put lambda in columns “b” and “c” (all the symbols in FOLLOW(A)).
We can apply these rules to all of the productions and we end up with the parse table :
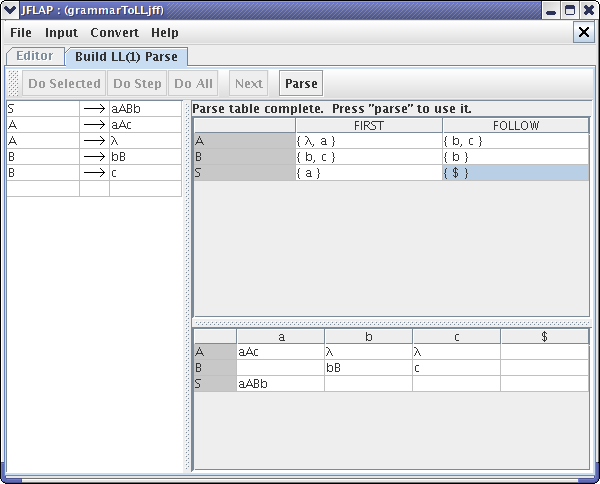
NOTE : If you click Do All, JFLAP will automatically perform all of the above tasks for you. If you click Do Step button, JFLAP will create FIRST set, then FOLLOW set, and finally parse table as you click the button.
Now we are finished with creating LL(1) Parse table, we can use this table to parse. Click on Parse button and your window should look like this :
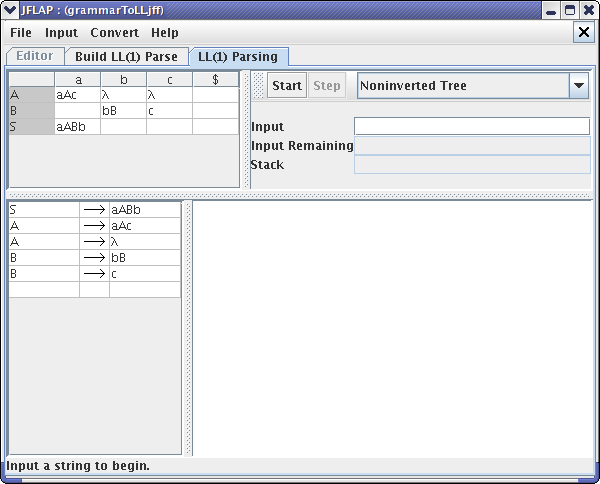
Now, let's parse the string “aacbbcb”. Enter this string in the Input text box and click on Start.
After clicking Start, at first nothing is going to show on the tree panel. However, JFLAP will notify you what input string is remaining to be parsed. After clicking Step once, your window should look like this :
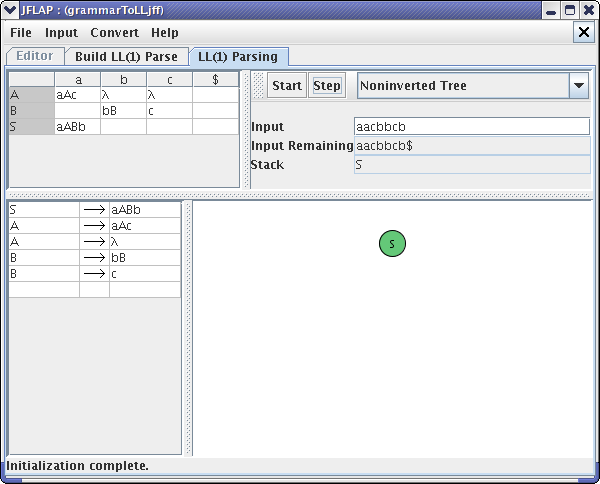
Note the input string is listed by “Input Remaining” with the special ending symbol $ added to the right end. Also note the start variable “S” has been placed on the stack. After clicking on Step again, your window should look like :
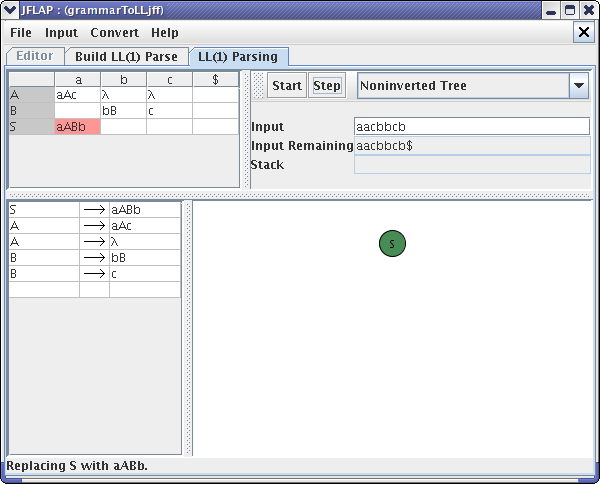
The variable “S” has been popped off the stack and is going to be replaced by its right-side. The red highlighted portion in the parse table tells you that JFLAP is going to apply that production to the current variable, in this case “S”. Also, there is a message at the bottom of the window which tells you what production JFLAP is applying to the variable. After clicking the Step button twice more, your window would look like :
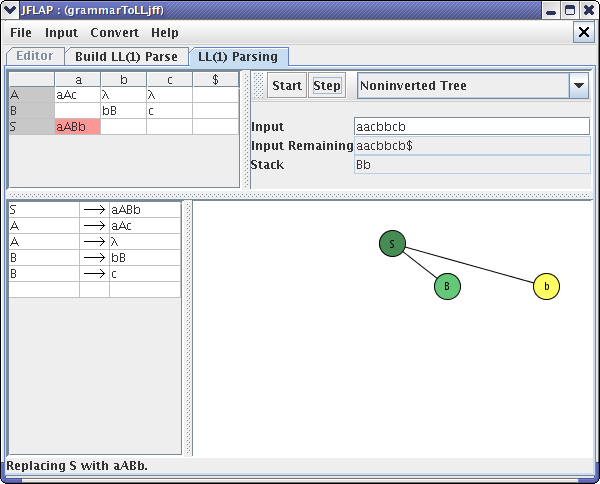
Notice that the stack is filling up with the right side of the production. A stack stores variables and terminals from right sides of productions. Variables are popped off the stack and replaced by the right side of a production, and terminals are popped off and matched in the order they appear in the string. After clicking the Step button twice more, your window would look like :

Notice how the right-side of “S->aABb” is now on the stack. In the next Step, JFLAP matches the “a” on top of the stack with the first “a” in the Input Remaining and removes both of them. This step is shown in this window, after you click the Step button.
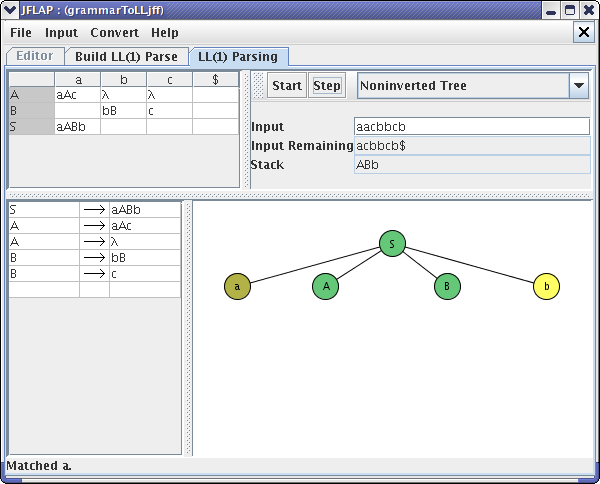
JFLAP puts the message at the bottom of the window that tells you that JFLAP matched the first terminal “a”. You can also see this process using the Derivation Table and Inverted Tree. After clicking the Step button numerous times, you will finally reach the end of the parsing. Your final window should look like one of these :
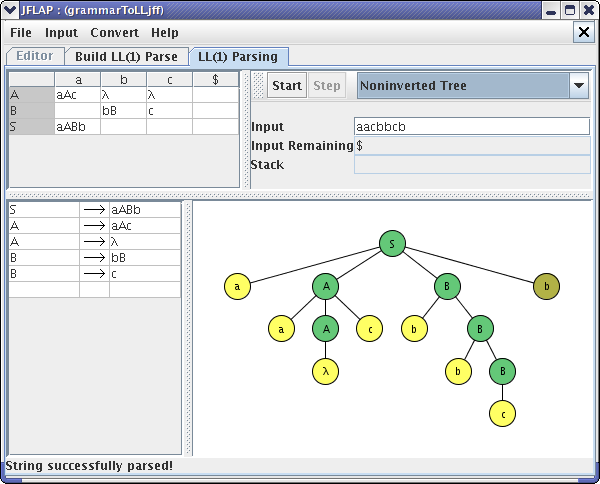
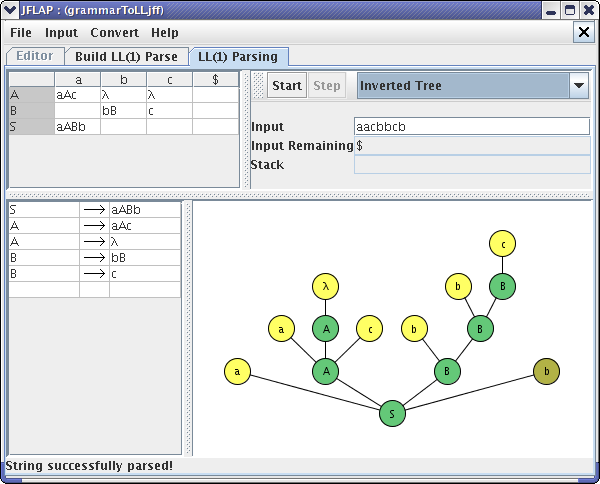
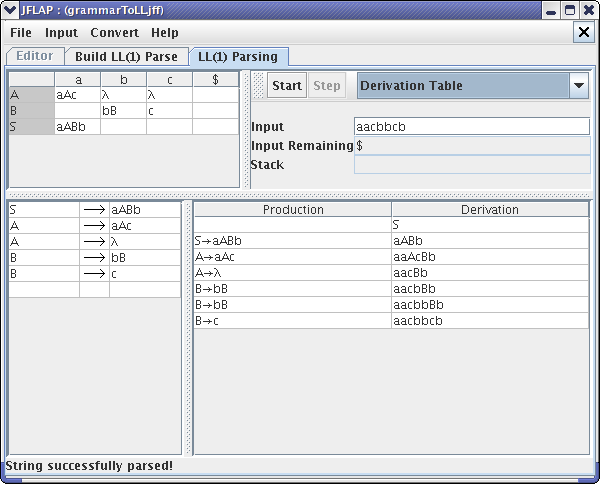
This concludes our brief tutorial on Building LL(1) Parse Table. Thanks for reading!